먼가 잘못됐다?
잘 돌아가던 서버가 어느 날 갑자기 응답을 멈췄을 때, 엔지니어가 가장 먼저 확인하는 것은 로그(Log)입니다. 블로그 운영도 시스템 엔지니어링과 크게 다르지 않습니다. 트래픽이 곤두박질치고 구글 유입이 0에 수렴한다면, 분명 어딘가에 치명적인 병목 현상이나 라우팅 오류가 발생했다는 뜻입니다.
최근 운영 중인 IT 블로그에서 심각한 장애가 발생했습니다. 무려 3개월째 구글 색인 생성이 완전히 멈춰버렸고, 구글 서치콘솔(Search Console)의 페이지 색인 메뉴에서는 '알려진 페이지만 보기' 콤보박스 자체가 비활성화(Disabled) 되어 클릭조차 되지 않는 기현상을 겪었습니다.
단순한 일시적 오류가 아니었습니다. 로그와 서버 데이터를 뜯어보듯 서치콘솔의 크롤링 통계를 분석해 본 결과, 철저하게 제 자신의 오판에서 비롯된 두 가지 치명적인 원인을 발견했습니다. 오늘은 구글 봇의 크롤링을 마비시킨 기술적 장애 원인과, AI 양산형 콘텐츠가 초래한 패널티, 그리고 이를 복구하기 위한 트러블슈팅 과정을 공유합니다.
1. 기술적 원인: 대규모 404 에러와 라우팅 맵핑의 붕괴
시스템 운영에서 가장 피해야 할 작업 중 하나가 '사전 대비 없는 대규모 마이그레이션'입니다. 저는 최근 블로그 아키텍처를 변경하면서 두 가지 큰 실수를 동시에 저질렀습니다.
첫째, 트래픽에 도움이 되지 않는다고 판단한 과거 포스팅 1,600여 개를 한 번에 삭제했습니다. 둘째, 이와 동시에 블로그의 URL 주소 체계를 기존 '숫자형(예: /123)'에서 구글 SEO에 좋다는 '문자형(예: /post-title)'으로 전면 개편했습니다.
이 두 작업이 맞물리면서 구글 크롤러 입장에서는 그야말로 대재앙이 일어났습니다. 구글 봇이 기존에 알고 있던 1,600개의 인덱스(Index) 데이터가 하루아침에 점점 404 Not Found 에러를 뿜어냈고, 살아남은 글들조차 URL 구조가 바뀌어버려 엄청난 리다이렉션(Redirection) 루프와 라우팅 맵핑 꼬임을 유발했습니다.
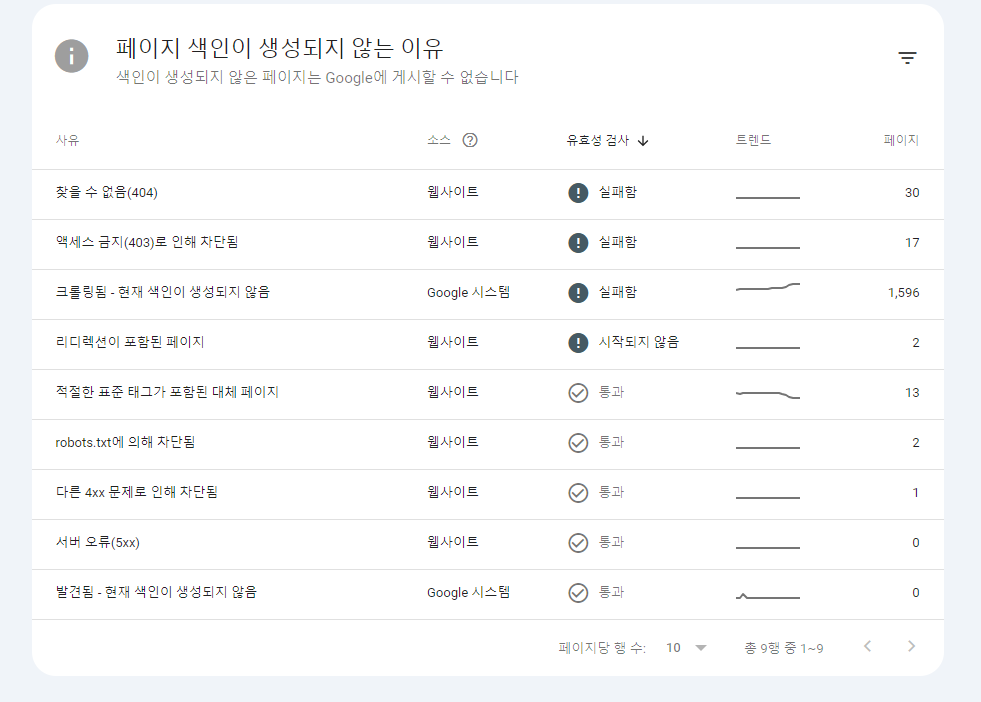
구글 봇에게 할당된 '크롤링 버짓(Crawl Budget, 크롤링 예산)'은 무한하지 않습니다. 봇은 길을 잃고 404 에러 페이지를 헤매느라 예산을 탕진했고, 결국 새로운 글을 수집할 여력을 완전히 상실해 버렸습니다. 콤보박스가 Disabled 된 것은 구글 봇이 해당 사이트의 URL 구조를 신뢰하지 못해 인덱싱 파이프라인 가동을 임시 중단한 것이나 다름없었습니다.
2. 콘텐츠 원인: HCU 알고리즘 철퇴와 AI 자동 생성의 한계
기술적 오류가 크롤링을 막았다면, 색인 누락의 쐐기를 박은 것은 '콘텐츠의 질'이었습니다.
최근 트래픽 볼륨을 빠르게 키워보겠다는 얄팍한 생각으로 100% AI 자동 생성 툴을 연동하여 매일 1일 1포스팅을 찍어냈습니다. 프롬프트를 아무리 정교하게 짜더라도, AI가 만들어낸 글은 웹상에 널린 정보를 그럴싸하게 짜깁기한 수준을 벗어나지 못했습니다.
문제는 구글의 알고리즘이 생각보다 훨씬 정교하다는 것입니다. 구글은 최근 '도움이 되는 콘텐츠 업데이트(HCU, Helpful Content Update)'를 통해 독창성 없는 양산형 글들을 철저하게 스팸으로 분류하고 있습니다. 시스템 분석 결과, 제 블로그는 이 HCU 필터링에 정확히 걸려들었습니다.

구글은 '크롤링'은 하되, 이 문서가 검색 엔진 데이터베이스에 저장(색인)할 가치가 없다고 판단한 것입니다. 껍데기만 번지르르할 뿐, 작성자의 고뇌나 실제 경험이 결여된 AI 텍스트 더미는 결국 블로그 도메인 전체의 신뢰도 점수를 바닥으로 끌어내렸습니다.
3. 트러블슈팅 및 복구 작업: 수질 정화와 진짜 경험(EEAT)의 기록
원인을 파악했으니 남은 것은 시스템 정상화 작업입니다. 장애 복구(Disaster Recovery)의 첫 단계는 오염된 데이터를 격리하는 것입니다.
우선, 그동안 기계적으로 찍어냈던 AI 양산형 글 600여 개를 즉각 비공개 처리(Triage)했습니다. 단기적인 트래픽 하락은 불가피하겠지만, 죽어버린 도메인 신뢰도를 회복하기 위한 뼈아픈 수질 정화 작업이었습니다. 또한 404 에러가 발생한 주요 URL들은 301 리다이렉트를 통해 정상적인 카테고리나 홈 화면으로 연결하여 크롤러의 길을 다시 터주었습니다.

앞으로는 구글이 검색 평가 가이드라인에서 가장 강조하는 EEAT(경험 Experience, 전문성 Expertise, 권위성 Authoritativeness, 신뢰성 Trustworthiness)를 충족하는 글만 작성하기로 정책을 바꿨습니다. 지금 여러분이 읽고 계신 이 글처럼 말이죠.
어디서나 볼 수 있는 뻔한 개념 설명이 아니라, 제가 직접 서버를 만지며 겪은 에러 상황, 삽질했던 과정, 스크린샷이 첨부된 진짜 해결책만을 기록할 것입니다. AI는 텍스트를 나열할 순 있어도 '경험'을 대체할 수는 없습니다.
결론적으로 24년간 C#, VB.NET 등 다양한 언어로 시스템을 구축해온 개발자로서, 이번 구글 서치 콘솔의 에러는 마치 런타임 오류를 잡는 것과 같았습니다.
마치며
블로그의 검색 엔진 최적화(SEO)는 꼼수로 봇을 속이는 작업이 아닙니다. 서버와 클라이언트가 정확한 프로토콜로 통신하듯, 가치 있는 데이터를 사용자에게 빠르고 정확하게 전달하는 구조를 만드는 일련의 아키텍처 설계입니다.
이번 3개월간의 색인 누락 사태는 시스템 엔지니어로서 기본기를 잊고 자동화의 함정에 빠졌던 뼈아픈 장애였습니다. 600개의 글을 덜어내고 바닥부터 다시 다지는 이 트러블슈팅 과정이 언제쯤 완전히 끝날지는 알 수 없습니다. 하지만 로그는 거짓말을 하지 않기에, 방향을 제대로 잡았다면 트래픽은 다시 정상 궤도로 복구될 것입니다.
비슷한 서치콘솔 에러를 겪고 계신 분들에게 이 디버깅 기록이 도움이 되길 바랍니다. 데이터가 유의미하게 반등하는 시점에 후속 모니터링 결과를 다시 포스팅하겠습니다.



